ZFSの性能を測るのはよくやられているが、スループットを測るだけのことが多い。CPU使用率は?ストレージのアクセスパターンは?圧縮とか暗号化を使った場合は?
いつも通り、ガバガバベンチマークなので鵜呑みにしないこと。
ZFSのバージョンも、ZFSは素人なので、見るべき値が間違っているかもしれない(特に圧縮の効果測定は間違ってると思う)
前提
- zfs v2.2.3 の kmod
- mirror vdevは 8diskを4mirrorにしたプール(RAID10のようなもの)
- RAID-Z2は 8diskを1つにしたプール (RAID-6のようなもの)
計測はfioで書き込みに使うデータはシステムSSD上にあるWikipediaの要約データ(XML,2.5GB)を使用し、bs=1Mで最大10GB、3分間(Ramp-up 15秒)計測。
計測中はvmstatによるCPU使用率, zpool iostatによる各ストレージの使用状況、zfs listのUSED(使用中)を1秒毎に計測した。
CPUは物理6コア/論理12コア。vmstatの使用率は全コアを100%とした場合なので注意。
設定とかコマンドとか
fioの設定ファイル
01-seq-write.fio
[global] ioengine=libaio direct=1 rw=write bs=1M runtime=3m time_based=1 ramp_time=15s numjobs=1 iodepth=8 buffer_pattern='test.dat' verify=pattern verify_pattern='test.dat' [seq_write] directory=/zfs-test filename_format=seq_file.$jobnum size=10G
02-seq-read.fio
[global] ioengine=libaio direct=1 rw=read bs=1M runtime=3m time_based=1 ramp_time=15s numjobs=1 iodepth=8 buffer_pattern='test.dat' verify=pattern verify_pattern='test.dat' [seq_read] directory=/zfs-test filename_format=seq_file.$jobnum size=10G
zpool作成
# HDDのシリアル末尾3桁を8台分使ってRAIDを組む # mirror vdev zpool create -O mountpoint=none zpool0 \ mirror /dev/disk/by-id/ata-WDC_*{4Y2,1C0} \ mirror /dev/disk/by-id/ata-WDC_*{4DD,HVK} \ mirror /dev/disk/by-id/ata-WDC_*{5JA,UXL} \ mirror /dev/disk/by-id/ata-WDC_*{A38,33T} # RAID-Z2 zpool create -O mountpoint=none zpool0 \ raidz2 /dev/disk/by-id/ata-WDC_*{4Y2,1C0} \ /dev/disk/by-id/ata-WDC_*{4DD,HVK} \ /dev/disk/by-id/ata-WDC_*{5JA,UXL} \ /dev/disk/by-id/ata-WDC_*{A38,33T} \
ZFSの設定
# アクセス時間 無効 zfs set atime=none pool0 # ※ベンチマーク用 APC,L2ARC(読み取りキャッシュ)を無効化(有効化してあるとREADが速すぎてしまうため) zfs set primarycache=none pool0 zfs set secondarycache=none pool0
dataset作成例(compress,encryptionは計測する内容に合わせて変動)
zfs create \ -o compression=off \ -o encryption=aes-256-gcm -o keylocation=file:///etc/zfs/pool.key -o keyformat=raw \ -o acltype=posixacl \ -o atime=off -o dnodesize=auto -o normalization=formD -o relatime=on -o xattr=sa \ -o mountpoint=/zfs-test zpool0/zfs-test
ベンチマークに使ったスクリプトとか、グラフ生成(python)のコードとか、計測ログとかについては、環境情報のマスクがめんどいし、誰も興味ないだろうから公開はしない。
ディスクへ直接ZFSプール vs GPTパーティションの上にZFSプール(暗号化の影響もついでに)
- GPTパーティションを使った時とそうでないときで差がないか確かめる
- ついでに暗号化の有効時・無効時のオーバーヘッドを確かめる
GPTパーティションをきるとラベルを付けることができ、/dev/disk/by-partlabel/ラベル名で参照できる。物理的なスロットに対応させたいときはGPTパーティションでラベル名に含めると便利ではないか?
でもZFSは何かのパーティションの上で動かすことは想定されているのか?オーバーヘッドがあるならどんなものがあるのか?
というわけで試してみた。
| 直接 | パーティション上 |
|---|---|
 |
 |
(※最下部のAllocated Spaceはあまり意味がないので無視してください(zfs listのUSEDと同等と勘違いしていた))
- 非暗号化・非圧縮 / 書き込み・読み込み
- 非暗号化・圧縮(lz4) / 書き込み・読み込み
- 暗号化(aes-256-gcm)・非圧縮 / 書き込み・読み込み
- 暗号化(aes-256-gcm)・圧縮(lz4) / 書き込み・読み込み
- 暗号化(aes-256-gcm)・圧縮(zstd-3) / 書き込み・読み込み
計測はfioで書き込みに使うデータはランダムデータ、最大10GB、3分間(Ramp-up 15秒)計測。
このケースで書き込んでいるデータはランダムデータだったので、圧縮が機能していなかった。(圧縮が効いているとAllocated Spaceでも減少傾向になる)ただ、圧縮効果が薄そうであれば Early abortするから無駄にCPUを使わなくなるはずでは…zstd-3で絶望的にCPU使用率が増加してしまっている。一旦無視。
スループットは一緒だし、CPU使用率も大差ないので、GPTパーティションをきった上にZFSを作っても問題なさそう。
暗号化時は非暗号化時と比べ、CPU使用率で読み取り時で5%~10%増加で書き込み時はわずかに増える程度。これぐらいならスループットには影響なさそう。
なお、ここまできて/dev/disk/by-id/でシリアルが付いていることに気づいたので、パーティションはなくてもいいかな、という気持ちになった。なんで今まで気づかなかったん・・・
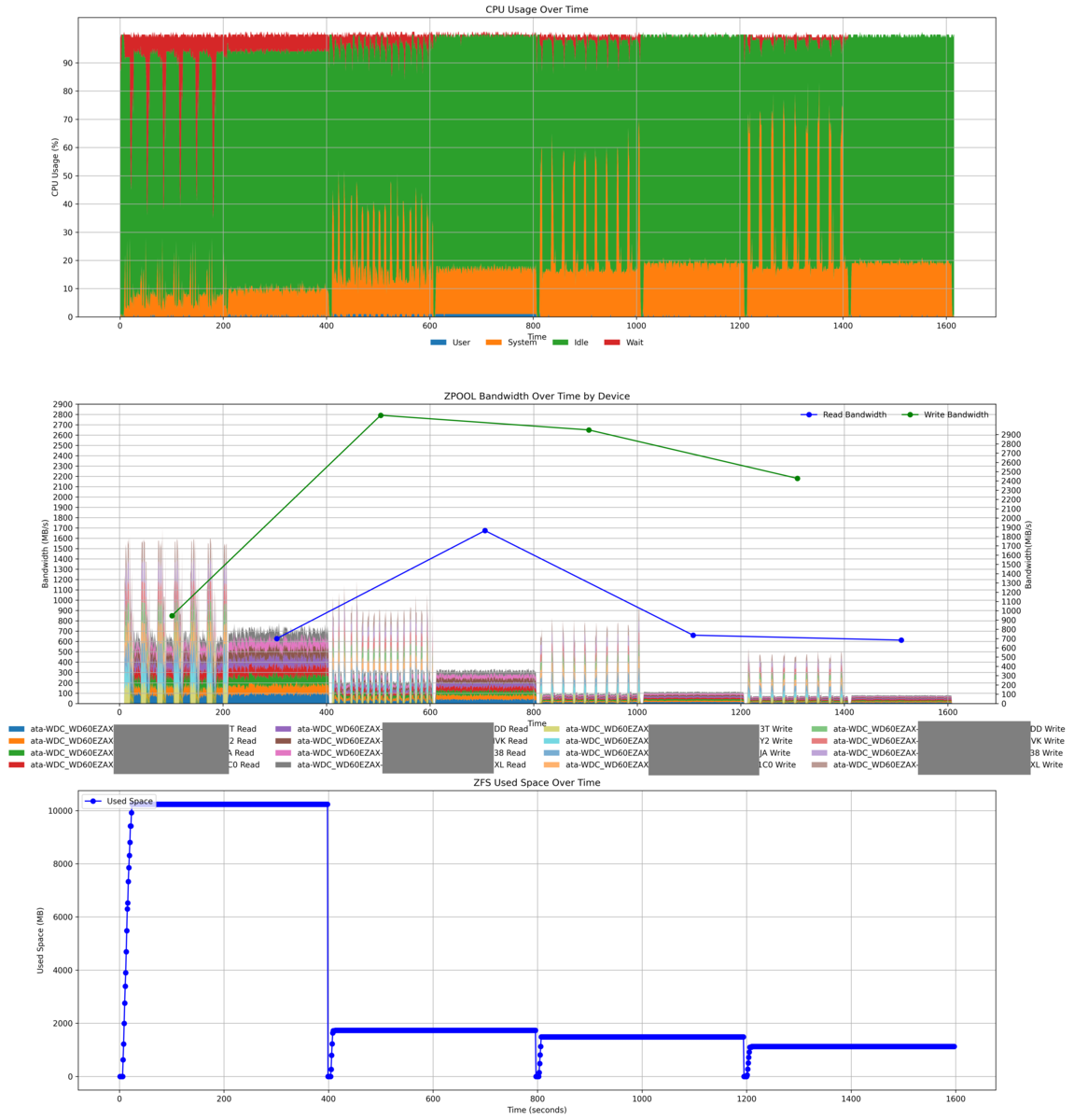
圧縮時のCPU使用率と性能(mirror vdev vs RAID-Z2)
- mirror vdevとRAID-Z2でCPU使用率やディスクのアクセス状況を見る
- 圧縮の効果を調べる
| mirror | raidz2 |
|---|---|
 |
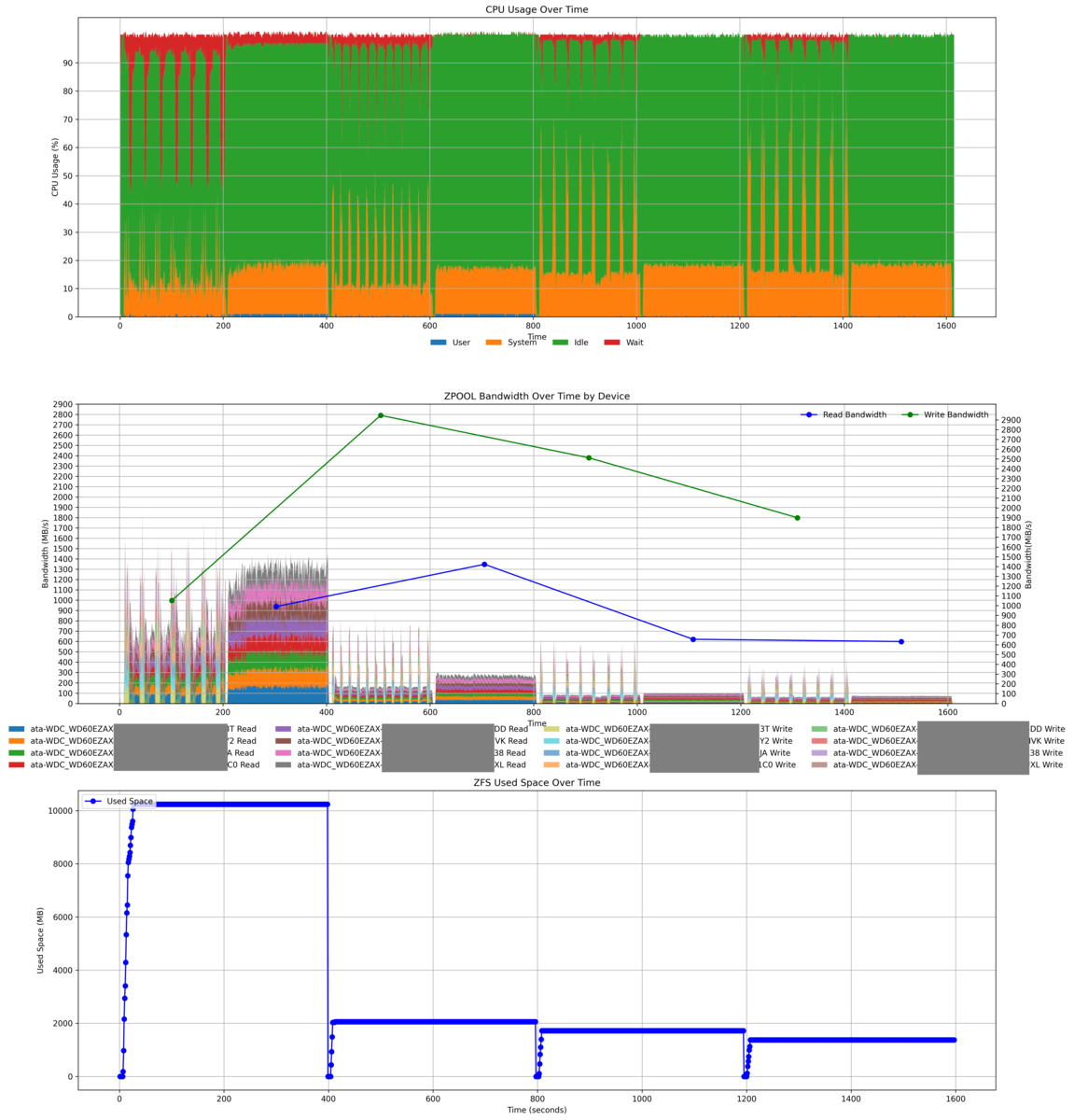 |
※書き込み時にREADが行われているのは多分fioのverifyだと思う
- 暗号化(aes-256-gcm)・圧縮(なし) / 書き込み・読み込み
- 暗号化(aes-256-gcm)・圧縮(lz4) / 書き込み・読み込み
- 暗号化(aes-256-gcm)・圧縮(zstd-fast-10) / 書き込み・読み込み
- 暗号化(aes-256-gcm)・圧縮(zstd-3) / 書き込み・読み込み
計測はfioで書き込みに使うデータはシステムSSD上にあるWikipediaのjawiki-latest-abstract.xml.gz (要約データ,XML,約2.3GB)を使用し、最大10GB、3分間(Ramp-up 15秒)計測。(テキストデータで圧縮効果を調べる)
単純なスループットを見たい場合は最初の圧縮無しを見る。
- Mirror
- WRITE時の負荷が高い(全ディスクへ書き込みが起きている。Mirrorの性質上仕方がない)
- READ時は負荷が分散できているように見える
- RAID-Z2
あと、なぜかわずかにmirror venvのほうが圧縮が効いてる。
圧縮形式の比較
- 共通
- このケースではREADのCPUのwaitは減っている
- ディスクのスループットも控えめ。圧縮データなので読み取る量も少ないからか?
- lz4
- 圧縮ありの中ではわずかに圧縮率が悪い
- スループットは最も高い
- 圧縮無しと比べ、CPU使用率もWRITEで約20%、READ時で約10%増えているが、この中では最も少ない
- zstd-fast-10
- zstd-3
- もっとも圧縮が効いている
- zstd-fast-10と比べ、さらにスループットが低下
- CPU使用率はlz4と同じぐらい
- zstd-fast10と比べ、CPU使用率もWRITEで約10%増えている (圧縮無しと比べるとWRITE+40%,READ+13%)
まとめ
mirror venvで運用しようかな、と思い始めていたが、btrfsのRAID10でもいいのではという気がしてきた。どうするかなぁ。
蛇足
fioのベンチマーク時に指定したデータでベンチマークする際はbuffer_patternで行えるが、3.34以上でないと512byte分を繰り返し書き込むだけなので注意
fioでベンチマーク取ろうとしたらハマってた。
buffer_pattern='test.dat' verify=pattern verify_pattern='test.dat'
'test.dat'とすると、test.datファイルの内容を元にベンチマークで書き込むようになる。
…のはずなのだが、手元では掲題の通りだった。
これは以下の修正が3.34以降でないと取り込まれていないためだった。検証時は3.33だった。
options: Support arbitrarily long pattern buffers · axboe/fio@1dc47d6 · GitHub
というのも、debian系のリポジトリで公開されているのが2025/01時点で3.33までしか存在しないため、知らずに未対応のバージョンを使っていたのであった。
最新版はソースコードからビルドする必要があるが、注意点はengineでlibaioを使う場合はlibaioのライブラリ(apt install libaio-dev)をビルド前に入れておくぐらい。簡単にビルドできる。
ZFSのcompressオプション
aes-256-gcmとaes-256-ccm(GCMとCCM)があるが、GCMのほうが並列処理に向いているのでGCMを選べばよい。
ZFSの思っているところ
これは後で書くかもしれない。素人が思ってる今の感想。ZFS、ファイルシステムとしては結構いいのでは、と思いはじめている。
個人的にファイルシステム(と、その下のレイヤを含むもの)で求めているもの。
特に最近、mdadm+XFSでは完全性は保証されなさそうであるというのがわかり、今まで綱渡りみたいな状態で運用していたのではないかと思っていた。
Btrfsも 上記の仕組みは透過暗号化以外は持っているっぽいので、使う価値はありそうな気がしている。